Streaming Delta Load with Late Arriving and Out of Order Events (with and without watermarking)¶
How to Deal with Late Arriving Data without using Watermark¶
This scenario covers a delta load in streaming mode that is able to deal with late arriving and out of order events.
As for other cases, the acon configuration should be executed with load_data using:
{
"input_specs": [
{
"spec_id": "sales_source",
"read_type": "streaming",
"data_format": "csv",
"options": {
"header": true,
"delimiter": "|"
},
"location": "file:///app/tests/lakehouse/in/feature/delta_load/record_mode_cdc/late_arriving_changes/streaming/data"
}
],
"transform_specs": [
{
"spec_id": "transformed_sales_source",
"input_id": "sales_source",
"transformers": [
{
"function": "condense_record_mode_cdc",
"args": {
"business_key": [
"salesorder",
"item"
],
"ranking_key_desc": [
"extraction_timestamp",
"actrequest_timestamp",
"datapakid",
"partno",
"record"
],
"record_mode_col": "recordmode",
"valid_record_modes": [
"",
"N",
"R",
"D",
"X"
]
}
}
]
}
],
"output_specs": [
{
"spec_id": "sales_bronze",
"input_id": "transformed_sales_source",
"write_type": "merge",
"data_format": "delta",
"location": "file:///app/tests/lakehouse/out/feature/delta_load/record_mode_cdc/late_arriving_changes/streaming/data",
"options": {
"checkpointLocation": "file:///app/tests/lakehouse/out/feature/delta_load/record_mode_cdc/late_arriving_changes/streaming/checkpoint"
},
"merge_opts": {
"merge_predicate": "current.salesorder = new.salesorder and current.item = new.item and current.date <=> new.date",
"update_predicate": "new.extraction_timestamp > current.extraction_timestamp or new.actrequest_timestamp > current.actrequest_timestamp or ( new.actrequest_timestamp = current.actrequest_timestamp and new.datapakid > current.datapakid) or ( new.actrequest_timestamp = current.actrequest_timestamp and new.datapakid = current.datapakid and new.partno > current.partno) or ( new.actrequest_timestamp = current.actrequest_timestamp and new.datapakid = current.datapakid and new.partno = current.partno and new.record >= current.record)",
"delete_predicate": "new.recordmode in ('R','D','X')",
"insert_predicate": "new.recordmode is null or new.recordmode not in ('R','D','X')"
}
}
],
"exec_env": {
"spark.sql.streaming.schemaInference": true
}
}
Relevant notes:¶
- First question we can impose is: Do we need such complicated update predicate to handle late arriving and out of order events? Simple answer is no. Because we expect that the latest event (e.g., latest status of a record in the source) will eventually arrive, and therefore the target delta lake table will eventually be consistent. However, when will that happen? Do we want to have our target table inconsistent until the next update comes along? This of course is only true when your source cannot ensure the order of the changes and cannot avoid late arriving changes (e.g., some changes that should have come in this changelog extraction, will only arrive in the next changelog extraction). From previous experiences, this is not the case with SAP BW, for example (as SAP BW is ACID compliant, and it will extract data from an SAP source and only have the updated changelog available when the extraction goes through, so theoretically we should not be able to extract data from the SAP BW changelog while SAP BW is still extracting data).
- However, when the source cannot fully ensure ordering (e.g., Kafka) and we want to make sure we don't load temporarily inconsistent data into the target table, we can pay extra special attention, as we do here, to our update and insert predicates, that will enable us to only insert or update data if the new event meets the respective predicates:
- In this scenario, we will only update if the
update_predicateis true, and that long predicate we have here ensures that the change that we are receiving is likely the latest one; - In this scenario, we will only insert the record if the record is not marked for deletion (this can happen if the new event is a record that is marked for deletion, but the record was not in the target table (late arriving changes where the delete came before the insert), and therefore, without the
insert_predicate, the algorithm would still try to insert the row, even if therecord_modeindicates that that row is for deletion. By using theinsert_predicateabove we avoid that to happen. However, even in such scenario, to prevent the algorithm to insert the data that comes later (which is old, as we said, the delete came before the insert and was actually the latest status), we would even need a more complex predicate based on your data's nature. Therefore, please read the disclaimer below. !!! note "Disclaimer!" The scenario illustrated in this page is purely fictional, designed for the Lakehouse Engine local tests specifically. Your data source changelogs may be different and the scenario and predicates discussed here may not make sense to you. Consequently, the data product team should reason about the adequate merge predicate and insert, update and delete predicates, that better reflect how they want to handle the delta loads for their data.
- In this scenario, we will only update if the
- We use spark.sql.streaming.schemaInference in our local tests only. We don't encourage you to use it in your data product.
Documentation
Feature Deep Dive: Watermarking in Apache Spark Structured Streaming - The Databricks Blog
Structured Streaming Programming Guide - Spark 3.4.0 Documentation
How to Deal with Late Arriving Data using Watermark¶
When building real-time pipelines, one of the realities that teams have to work with is that distributed data ingestion is inherently unordered. Additionally, in the context of stateful streaming operations, teams need to be able to properly track event time progress in the stream of data they are ingesting for the proper calculation of time-window aggregations and other stateful operations. While working with real-time streaming data there will be delays between event time and processing time due to how data is ingested and whether the overall application experiences issues like downtime. Due to these potential variable delays, the engine that you use to process this data needs to have some mechanism to decide when to close the aggregate windows and produce the aggregate result.
Imagine a scenario where we will need to perform stateful aggregations on the streaming data to understand and identify problems in the machines. This is where we need to leverage Structured Streaming and Watermarking to produce the necessary stateful aggregations.
Approach 1 - Use a pre-defined fixed window (Bad)¶
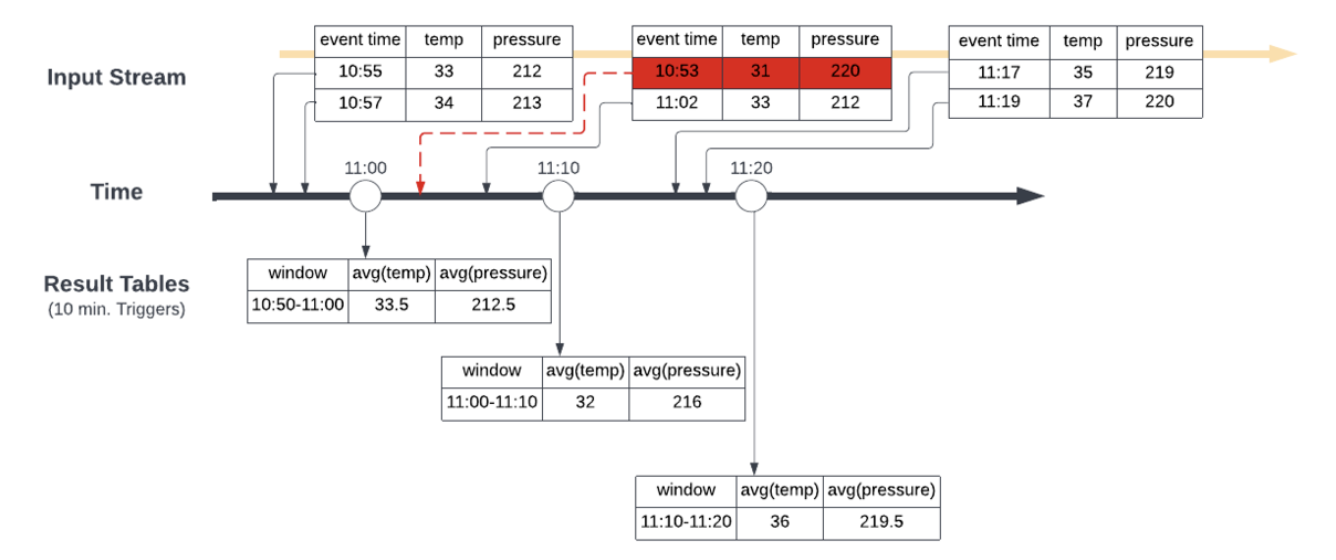
Credits: Image source
To explain this visually let’s take a scenario where we are receiving data at various times from around 10:50 AM → 11:20 AM. We are creating 10-minute tumbling windows that calculate the average of the temperature and pressure readings that came in during the windowed period.
In this first picture, we have the tumbling windows trigger at 11:00 AM, 11:10 AM and 11:20 AM leading to the result tables shown at the respective times. When the second batch of data comes around 11:10 AM with data that has an event time of 10:53 AM this gets incorporated into the temperature and pressure averages calculated for the 11:00 AM → 11:10 AM window that closes at 11:10 AM, which does not give the correct result.
Approach 2 - Watermark¶
We can define a watermark that will allow Spark to understand when to close the aggregate window and produce the correct aggregate result. In Structured Streaming applications, we can ensure that all relevant data for the aggregations we want to calculate is collected by using a feature called watermarking. In the most basic sense, by defining a watermark Spark Structured Streaming then knows when it has ingested all data up to some time, T, (based on a set lateness expectation) so that it can close and produce windowed aggregates up to timestamp T.
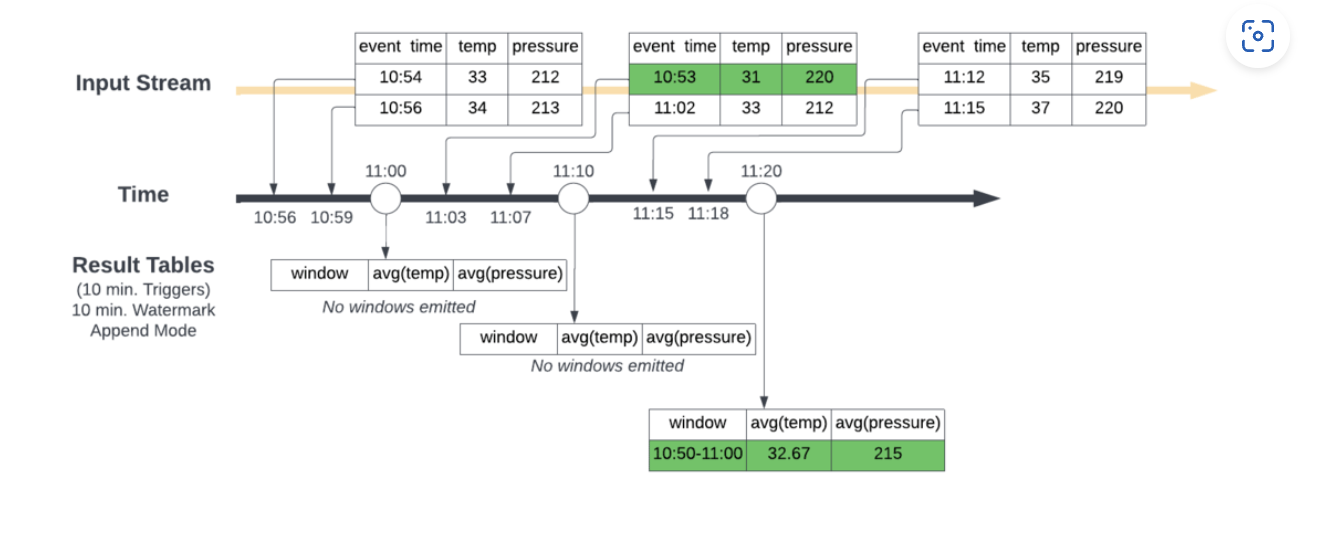
Credits: Image source
Unlike the first scenario where Spark will emit the windowed aggregation for the previous ten minutes every ten minutes (i.e. emit the 11:00 AM →11:10 AM window at 11:10 AM), Spark now waits to close and output the windowed aggregation once the max event time seen minus the specified watermark is greater than the upper bound of the window.
In other words, Spark needed to wait until it saw data points where the latest event time seen minus 10 minutes was greater than 11:00 AM to emit the 10:50 AM → 11:00 AM aggregate window. At 11:00 AM, it does not see this, so it only initialises the aggregate calculation in Spark’s internal state store. At 11:10 AM, this condition is still not met, but we have a new data point for 10:53 AM so the internal state gets updated, just not emitted. Then finally by 11:20 AM Spark has seen a data point with an event time of 11:15 AM and since 11:15 AM minus 10 minutes is 11:05 AM which is later than 11:00 AM the 10:50 AM → 11:00 AM window can be emitted to the result table.
This produces the correct result by properly incorporating the data based on the expected lateness defined by the watermark. Once the results are emitted the corresponding state is removed from the state store.
Watermarking and Different Output Modes¶
It is important to understand how state, late-arriving records, and the different output modes could lead to different behaviours of your application running on Spark. The main takeaway here is that in both append and update modes, once the watermark indicates that all data is received for an aggregate time window, the engine can trim the window state. In append mode the aggregate is produced only at the closing of the time window plus the watermark delay while in update mode it is produced on every update to the window.
Lastly, by increasing your watermark delay window you will cause the pipeline to wait longer for data and potentially drop less data – higher precision, but also higher latency to produce the aggregates. On the flip side, smaller watermark delay leads to lower precision but also lower latency to produce the aggregates.
Watermarks can only be used when you are running your streaming application in append or update output modes. There is a third output mode, complete mode, in which the entire result table is written to storage. This mode cannot be used because it requires all aggregate data to be preserved, and hence cannot use watermarking to drop intermediate state.
Joins With Watermark¶
There are three types of stream-stream joins that can be implemented in Structured Streaming: inner, outer, and semi joins. The main problem with doing joins in streaming applications is that you may have an incomplete picture of one side of the join. Giving Spark an understanding of when there are no future matches to expect is similar to the earlier problem with aggregations where Spark needed to understand when there were no new rows to incorporate into the calculation for the aggregation before emitting it.
To allow Spark to handle this, we can leverage a combination of watermarks and event-time constraints within the join condition of the stream-stream join. This combination allows Spark to filter out late records and trim the state for the join operation through a time range condition on the join.
Spark has a policy for handling multiple watermark definitions. Spark maintains one global watermark that is based on the slowest stream to ensure the highest amount of safety when it comes to not missing data.
We can change this behaviour by changing spark.sql.streaming.multipleWatermarkPolicy to max; however, this means that data from the slower stream will be dropped.
State Store Performance Considerations¶
As of Spark 3.2, Spark offers RocksDB state store provider.
If you have stateful operations in your streaming query (for example, streaming aggregation, streaming dropDuplicates, stream-stream joins, mapGroupsWithState, or flatMapGroupsWithState) and you want to maintain millions of keys in the state, then you may face issues related to large JVM garbage collection (GC) pauses causing high variations in the micro-batch processing times. This occurs because, by the implementation of HDFSBackedStateStore, the state data is maintained in the JVM memory of the executors and large number of state objects puts memory pressure on the JVM causing high GC pauses.
In such cases, you can choose to use a more optimized state management solution based on RocksDB. Rather than keeping the state in the JVM memory, this solution uses RocksDB to efficiently manage the state in the native memory and the local disk. Furthermore, any changes to this state are automatically saved by Structured Streaming to the checkpoint location you have provided, thus providing full fault-tolerance guarantees (the same as default state management).
To enable the new build-in state store implementation, set spark.sql.streaming.stateStore.providerClass to org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider.
For more details please visit Spark documentation: https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#rocksdb-state-store-implementation
You can enable this in your acons, by specifying it as part of the exec_env properties like below: