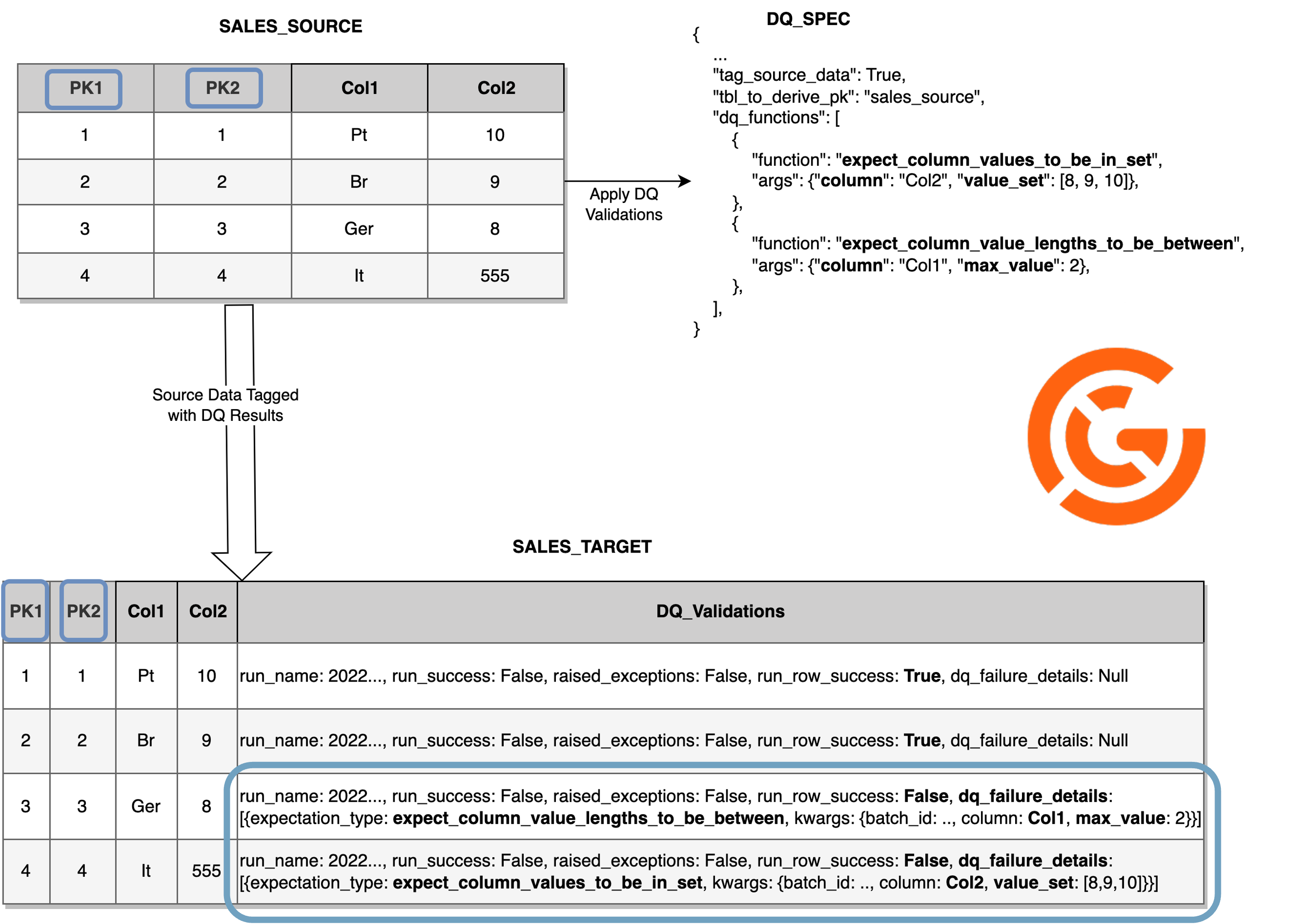
Row Tagging
Data quality is essential for any organisation that relies on data to make informed decisions. High-quality data provides accurate, reliable, and timely information that enables organisations to identify opportunities, mitigate risks, and optimize their operations. In contrast, low-quality data can lead to incorrect conclusions, faulty decisions, and wasted resources.
There are several common issues that can compromise data quality, such as:
- data entry errors;
- data duplication;
- incomplete / inconsistent data;
- changes where data is collected (e.g. sources);
- faulty data processing, such as inaccurate data cleansing or transformations.
Therefore, implementing data quality controls, such as data validation rules, and regularly monitoring data for accuracy and completeness is key for any organisation.
One of these controls that can be applied is the DQ Row Tagging Strategy so that you not only apply validations on your data to ensure Data Quality, but you also tag your data with the results of the Data Quality validations providing advantages like:
- Transparency for downstream and upstream consumers;
- Data Observability and Reliability;
- More trust over the data;
- Anomaly Detection;
- Easier and faster discovery of Data Quality problems, and, consequently faster resolution;
- Makes it easier to deal with integrations with other systems and migrations (you can have validations capturing that a column was changed or simply disappeared);
When using the DQ Row Tagging approach data availability will take precedence over Data Quality, meaning that all the data will be introduced into the final target (e.g. table or location) no matter what Data Quality issues it is having.
Different Types of Expectations:
- Table Level
- Column Aggregated Level
- Query Level
- Column Values (row level)
- Column Pair Value (row level)
- Multicolumn Values (row level)
The expectations highlighted as row level will be the ones enabling to Tag failures on specific rows and adding the details about each failure (they affect the field run_row_result inside dq_validations). The expectations with other levels (not row level) influence the overall result of the Data Quality execution, but won't be used to tag specific rows (they affect the field run_success only, so you can even have situations for which you get run_success False and run_row_success True for all rows).
How does the Strategy work?
The strategy relies mostly on the 6 below arguments.
When you specify "tag_source_data": True the arguments fail_on_error, gx_result_format and
result_sink_explode are set to the expected values.
- unexpected_rows_pk - the list columns composing the primary key of the source data to use to identify the rows failing the DQ validations.
- tbl_to_derive_pk -
db.tableto automatically derive the unexpected_rows_pk from. - gx_result_format - great expectations result format. Default:
COMPLETE. - tag_source_data - flag to enable the tagging strategy in the source data, adding the information of
the DQ results in a column
dq_validations. This column makes it possible to identify if the DQ run was succeeded in general and, if not, it unlocks the insights to know what specific rows have made the DQ validations fail and why. Default:False.
It only works if result_sink_explode is True, result_format is COMPLETE and
fail_on_error is `False.
- fail_on_error - whether to fail the algorithm if the validations of your data in the DQ process failed.
- result_sink_explode - flag to determine if the output table/location should have the columns exploded (as
True) or not (asFalse). Default:True.
It is mandatory to provide one of the arguments (unexpected_rows_pk or tbl_to_derive_pk) when using tag_source_data as True. When tag_source_data is False, this is not mandatory, but still recommended.
The tagging strategy only works when tag_source_data is True, which automatically
assigns the expected values for the parameters result_sink_explode (True), fail_on_error (False)
and gx_result_format ("COMPLETE").
For the DQ Row Tagging to work, in addition to configuring the aforementioned arguments in the dq_specs, you will also need to add the dq_validations field into your table (your DDL statements, recommended) or enable schema evolution.
Kwargs field is a string, because it can assume different schemas for different expectations and runs. It is useful to provide the complete picture of the row level failure and to allow filtering/joining with the result sink table, when there is one. Some examples of kwargs bellow:
{"column": "country", "min_value": 1, "max_value": 2, "batch_id": "o723491yyr507ho4nf3"}→ example for expectations starting withexpect_column_values(they always make use of "column", the other arguments vary).{"column_A: "country", "column_B": "city", "batch_id": "o723491yyr507ho4nf3"}→ example for expectations starting withexpect_column_pair(they make use of "column_A" and "column_B", the other arguments vary).{"column_list": ["col1", "col2", "col3"], "batch_id": "o723491yyr507ho4nf3"}→ example for expectations starting withexpect_multicolumn(they make use of "column_list", the other arguments vary).batch_idis common to all expectations, and it is an identifier for the batch of data being validated by Great Expectations.
Example
This scenario uses the row tagging strategy which allow users to tag the rows that failed to be easier to identify the problems in the validations.
from lakehouse_engine.engine import load_data
acon = {
"input_specs": [
{
"spec_id": "dummy_deliveries_source",
"read_type": "batch",
"data_format": "csv",
"options": {
"header": True,
"delimiter": "|",
"inferSchema": True,
},
"location": "s3://my_data_product_bucket/dummy_deliveries/",
}
],
"dq_specs": [
{
"spec_id": "dq_validator",
"input_id": "dummy_deliveries_source",
"dq_type": "validator",
"bucket": "my_data_product_bucket",
"data_docs_bucket": "my_dq_data_docs_bucket }}",
"data_docs_prefix": "dq/my_data_product/data_docs/site/",
"result_sink_db_table": "my_database.dq_result_sink",
"result_sink_location": "my_dq_path/dq_result_sink/",
"tag_source_data": True,
"tbl_to_derive_pk": "my_database.dummy_deliveries",
"source": "deliveries_tag",
"dq_functions": [
{"function": "expect_column_to_exist", "args": {"column": "salesorder"}},
{"function": "expect_table_row_count_to_be_between", "args": {"min_value": 15, "max_value": 25}},
{
"function": "expect_column_values_to_be_in_set",
"args": {"column": "salesorder", "value_set": ["37"]},
},
{
"function": "expect_column_pair_a_to_be_smaller_or_equal_than_b",
"args": {"column_A": "salesorder", "column_B": "delivery_item"},
},
{
"function": "expect_multicolumn_sum_to_equal",
"args": {"column_list": ["salesorder", "delivery_item"], "sum_total": 100},
},
],
"critical_functions": [
{"function": "expect_table_column_count_to_be_between", "args": {"max_value": 6}},
],
}
],
"output_specs": [
{
"spec_id": "dummy_deliveries_bronze",
"input_id": "dq_validator",
"write_type": "overwrite",
"data_format": "delta",
"location": "s3://my_data_product_bucket/bronze/dummy_deliveries_dq_template/",
}
],
}
load_data(acon=acon)
Running bellow cell shows the new column created, named dq_validations with information about DQ validations.
display(spark.read.format("delta").load("s3://my_data_product_bucket/bronze/dummy_deliveries_dq_template/"))
Performance and Limitations Trade-offs
When using the DQ Row Tagging Strategy, by default we are using Great Expectations Result Format "Complete" with Unexpected Index Column Names (a primary key for the failures), meaning that for each failure, we are getting all the distinct values for the primary key. After getting all the failures, we are applying some needed transformations and joining them with the source data, so that it can be tagged by filling the "dq_validations" column.
Hence, this can definitely be a heavy and time-consuming operation on your data loads. To reduce this disadvantage
you can cache the dataframe by passing the "cache_df": True in your DQ Specs. In addition to this, always have in
mind that each expectation (dq_function) that you add into your DQ Specs, is more time that you are adding into your
data loads, so always balance performance vs amount of validations that you need.
Moreover, Great Expectations is currently relying on the driver node to capture the results of the execution and return/store them. Thus, in case you have huge amounts of rows failing (let's say 500k or more) Great Expectations might raise exceptions.
On these situations, the data load will still happen and the data will still be tagged with the Data Quality validations information, however you won't have the complete picture of the failures, so the raised_exceptions field is filled as True, so that you can easily notice it and debug it.
Most of the time, if you have such an amount of rows failing, it will probably mean that you did something wrong and want to fix it as soon as possible (you are not really caring about tagging specific rows, because you will not want your consumers to be consuming a million of defective rows). However, if you still want to try to make it pass, you can try to increase your driver and play with some spark configurations like:
spark.driver.maxResultSizespark.task.maxFailures
For debugging purposes, you can also use a different Great Expectations Result Format like "SUMMARY" (adding in your DQ Spec
"gx_result_format": "SUMMARY"), so that you get only a partial list of the failures, avoiding surpassing the driver
capacity.
When using a Result Format different from the default ("COMPLETE"), the flag "tag_source_data" will be
overwritten to False, as the results of the tagging wouldn't be complete which could lead to erroneous
conclusions from stakeholders (but you can always get the details about the result of the DQ execution in
the result_sink_location or result_sink_db_table that you have configured).