![]()
Lakehouse Engine
A configuration driven Spark framework, written in Python, serving as a scalable and distributed engine for several lakehouse algorithms, data flows and utilities for Data Products.
Note: whenever you read Data Product or Data Product team, we want to refer to Teams and use cases, whose main focus is on leveraging the power of data, on a particular topic, end-to-end (ingestion, consumption...) to achieve insights, supporting faster and better decisions, which generate value for their businesses. These Teams should not be focusing on building reusable frameworks, but on re-using the existing frameworks to achieve their goals.
Main Goals
The goal of the Lakehouse Engine is to bring some advantages, such as:
- offer cutting-edge, standard, governed and battle-tested foundations that several Data Product teams can benefit from;
- avoid that Data Product teams develop siloed solutions, reducing technical debts and high operating costs (redundant developments across teams);
- allow Data Product teams to focus mostly on data-related tasks, avoiding wasting time & resources on developing the same code for different use cases;
- benefit from the fact that many teams are reusing the same code, which increases the likelihood that common issues are surfaced and solved faster;
- decrease the dependency and learning curve to Spark and other technologies that the Lakehouse Engine abstracts;
- speed up repetitive tasks;
- reduced vendor lock-in.
Note: even though you will see a focus on AWS and Databricks, this is just due to the lack of use cases for other technologies like GCP and Azure, but we are open for contribution.
Key Features
⭐ Data Loads: perform data loads from diverse source types and apply transformations and data quality validations, ensuring trustworthy data, before integrating it into distinct target types. Additionally, people can also define termination actions like optimisations or notifications. On the usage section you will find an example using all the supported keywords for data loads.
Note: The Lakehouse Engine supports different types of sources and targets, such as, kafka, jdbc, dataframes, files (csv, parquet, json, delta...), sftp, sap bw, sap b4...
⭐ Transformations: configuration driven transformations without the need to write any spark code. Transformations can be applied by using the transform_specs in the Data Loads.
Note: you can search all the available transformations, as well as checking implementation details and examples here.
⭐ Data Quality Validations: the Lakehouse Engine uses Great Expectations as a backend and abstracts any implementation details by offering people the capability to specify what validations to apply on the data, solely using dict/json based configurations. The Data Quality validations can be applied on:
- post-mortem (static) data, using the DQ Validator algorithm (
execute_dq_validation) - data in-motion, using the
dq_specskeyword in the Data Loads, to add it as one more step while loading data. On the usage section you will find an example using this type of Data Quality validations.
⭐ Reconciliation: useful algorithm to compare two source of data, by defining one version of the truth to compare
against the current version of the data. It can be particularly useful during migrations phases, two compare a few KPIs
and ensure the new version of a table (current), for example, delivers the same vision of the data as the old one (truth).
Find usage examples here.
⭐ Sensors: an abstraction to otherwise complex spark code that can be executed in very small single-node clusters to check if an upstream system or Data Product contains new data since the last execution. With this feature, people can trigger jobs to run in more frequent intervals and if the upstream does not contain new data, then the rest of the job exits without creating bigger clusters to execute more intensive data ETL (Extraction, Transformation, and Loading). Find usage examples here.
⭐ Terminators: this feature allow people to specify what to do as a last action, before finishing a Data Load.
Some examples of actions are: optimising target table, vacuum, compute stats, expose change data feed to external location
or even send e-mail notifications. Thus, it is specifically used in Data Loads, using the terminate_specs keyword.
On the usage section you will find an example using terminators.
⭐ Table Manager: function manage_table, offers a set of actions to manipulate tables/views in several ways, such as:
- compute table statistics;
- create/drop tables and views;
- delete/truncate/repair tables;
- vacuum delta tables or locations;
- optimize table;
- describe table;
- show table properties;
- execute sql.
⭐ File Manager: function manage_files, offers a set of actions to manipulate files in several ways, such as:
- delete Objects in S3;
- copy Objects in S3;
- restore Objects from S3 Glacier;
- check the status of a restore from S3 Glacier;
- request a restore of objects from S3 Glacier and wait for them to be copied to a destination.
⭐ Notifications: you can configure and send email notifications.
Note: it can be used as an independent function (
send_notification) or as aterminator_spec, using the functionnotify.
📖 In case you want to check further details you can check the documentation of the Lakehouse Engine facade.
Installation
As the Lakehouse Engine is built as wheel (look into our build and deploy make targets) you can install it as any other python package using pip.
pip install lakehouse_engine
Alternatively, you can also upload the wheel to any target of your like (e.g. S3) and perform a pip installation pointing to that target location.
Note: It is advisable for a Data Product to pin a specific version of the Lakehouse Engine (and have recurring upgrading activities) to avoid breaking changes in a new release. In case you don't want to be so conservative, you can pin to a major version, which usually shouldn't include changes that break backwards compatibility.
How Data Products use the Lakehouse Engine Framework?
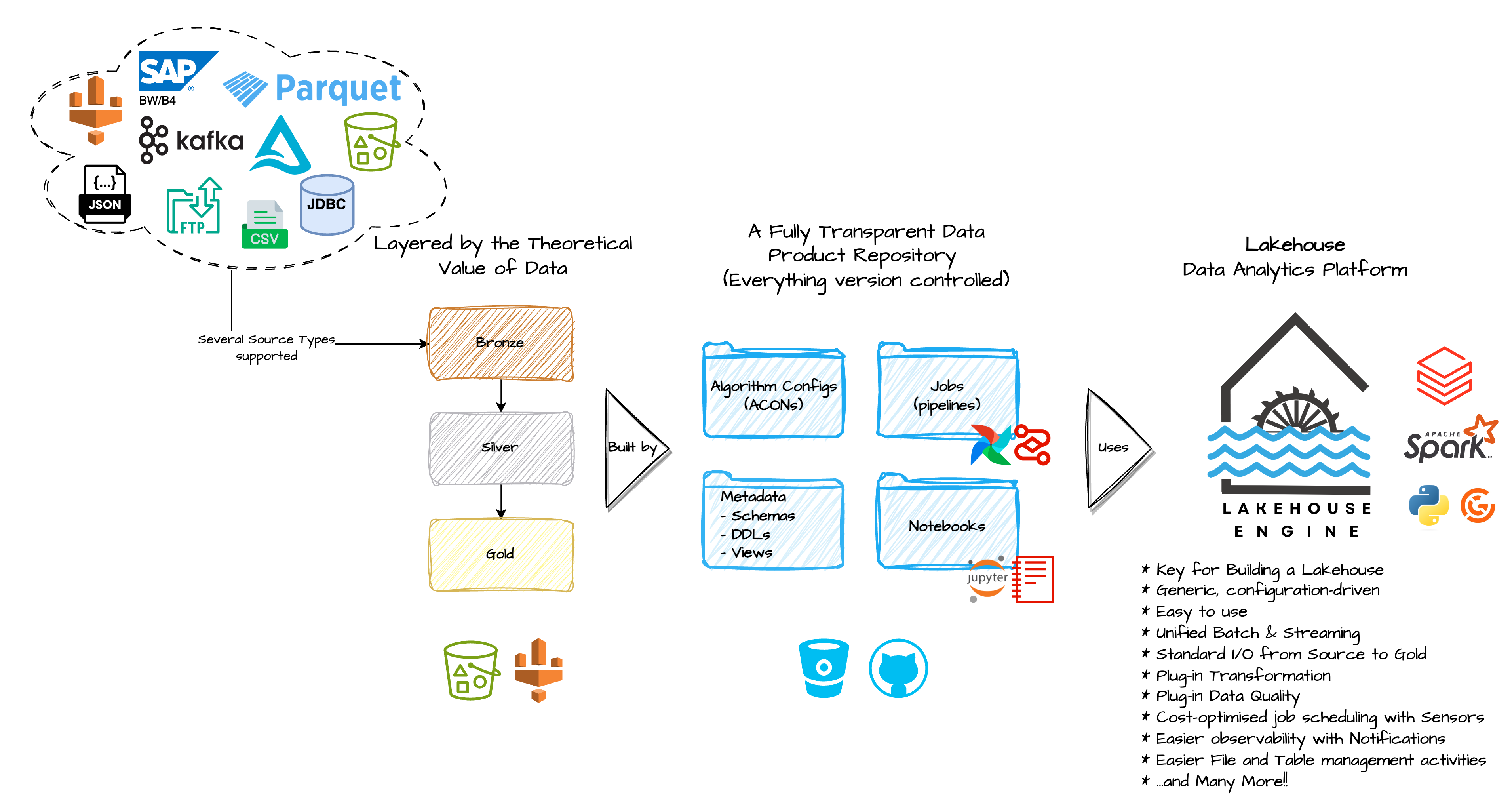
The Lakehouse Engine is a configuration-first Data Engineering framework, using the concept of ACONs to configure algorithms. An ACON, stands for Algorithm Configuration and is a JSON representation, as the Load Data Usage Example demonstrates.
Below you find described the main keywords you can use to configure and ACON for a Data Load.
Note: the usage logic for the other algorithms/features presented will always be similar, but using different keywords, which you can search for in the examples and documentation provided in the Key Features and Community Support and Contributing sections.
- Input specifications (input_specs): specify how to read data. This is a mandatory keyword.
- Transform specifications (transform_specs): specify how to transform data.
- Data quality specifications (dq_specs): specify how to execute the data quality process.
- Output specifications (output_specs): specify how to write data to the target. This is a mandatory keyword.
- Terminate specifications (terminate_specs): specify what to do after writing into the target (e.g., optimising target table, vacuum, compute stats, expose change data feed to external location, etc).
- Execution environment (exec_env): custom Spark session configurations to be provided for your algorithm (configurations can also be provided from your job/cluster configuration, which we highly advise you to do instead of passing performance related configs here for example).
Load Data Usage Example
You can use the Lakehouse Engine in a pyspark script or notebook. Below you can find an example on how to execute a Data Load using the Lakehouse Engine, which is doing the following:
- Read CSV files, from a specified location, in a streaming fashion and providing a specific schema and some additional options for properly read the files (e.g. header, delimiter...);
- Apply two transformations on the input data:
- Add a new column having the Row ID;
- Add a new column
extraction_date, which extracts the date from thelhe_extraction_filepath, based on a regex.
- Apply Data Quality validations and store the result of their execution in the table
your_database.order_events_dq_checks:- Check if the column
omnihub_locale_codeis not having null values; - Check if the distinct value count for the column
product_divisionis between 10 and 100; - Check if the max of the column
so_net_valueis between 10 and 1000; - Check if the length of the values in the column
omnihub_locale_codeis between 1 and 10; - Check if the mean of the values for the column
coupon_codeis between 15 and 20.
- Check if the column
- Write the output into the table
your_database.order_events_with_dqin a delta format, partitioned byorder_date_headerand applying a merge predicate condition, ensuring the data is only inserted into the table if it does not match the predicate (meaning the data is not yet available in the table). Moreover, theinsert_onlyflag is used to specify that there should not be any updates or deletes in the target table, only inserts; - Optimize the Delta Table that we just wrote in (e.g. z-ordering);
- Specify 3 custom Spark Session configurations.
⚠️ Note:
spec_idis one of the main concepts to ensure you can chain the steps of the algorithm, so, for example, you can specify the transformations (intransform_specs) of a DataFrame that was read in theinput_specs.
from lakehouse_engine.engine import load_data
acon = {
"input_specs": [
{
"spec_id": "orders_bronze",
"read_type": "streaming",
"data_format": "csv",
"schema_path": "s3://my-data-product-bucket/artefacts/metadata/bronze/schemas/orders.json",
"with_filepath": True,
"options": {
"badRecordsPath": "s3://my-data-product-bucket/badrecords/order_events_with_dq/",
"header": False,
"delimiter": "\u005E",
"dateFormat": "yyyyMMdd",
},
"location": "s3://my-data-product-bucket/bronze/orders/",
}
],
"transform_specs": [
{
"spec_id": "orders_bronze_with_extraction_date",
"input_id": "orders_bronze",
"transformers": [
{"function": "with_row_id"},
{
"function": "with_regex_value",
"args": {
"input_col": "lhe_extraction_filepath",
"output_col": "extraction_date",
"drop_input_col": True,
"regex": ".*WE_SO_SCL_(\\d+).csv",
},
},
],
}
],
"dq_specs": [
{
"spec_id": "check_orders_bronze_with_extraction_date",
"input_id": "orders_bronze_with_extraction_date",
"dq_type": "validator",
"result_sink_db_table": "your_database.order_events_dq_checks",
"fail_on_error": False,
"dq_functions": [
{
"dq_function": "expect_column_values_to_not_be_null",
"args": {
"column": "omnihub_locale_code"
}
},
{
"dq_function": "expect_column_unique_value_count_to_be_between",
"args": {
"column": "product_division",
"min_value": 10,
"max_value": 100
},
},
{
"dq_function": "expect_column_max_to_be_between",
"args": {
"column": "so_net_value",
"min_value": 10,
"max_value": 1000
}
},
{
"dq_function": "expect_column_value_lengths_to_be_between",
"args": {
"column": "omnihub_locale_code",
"min_value": 1,
"max_value": 10
},
},
{
"dq_function": "expect_column_mean_to_be_between",
"args": {
"column": "coupon_code",
"min_value": 15,
"max_value": 20
}
},
],
},
],
"output_specs": [
{
"spec_id": "orders_silver",
"input_id": "check_orders_bronze_with_extraction_date",
"data_format": "delta",
"write_type": "merge",
"partitions": ["order_date_header"],
"merge_opts": {
"merge_predicate": """
new.sales_order_header = current.sales_order_header
AND new.sales_order_schedule = current.sales_order_schedule
AND new.sales_order_item=current.sales_order_item
AND new.epoch_status=current.epoch_status
AND new.changed_on=current.changed_on
AND new.extraction_date=current.extraction_date
AND new.lhe_batch_id=current.lhe_batch_id
AND new.lhe_row_id=current.lhe_row_id
""",
"insert_only": True,
},
"db_table": "your_database.order_events_with_dq",
"options": {
"checkpointLocation": "s3://my-data-product-bucket/checkpoints/template_order_events_with_dq/"
},
}
],
"terminate_specs": [
{
"function": "optimize_dataset",
"args": {
"db_table": "your_database.order_events_with_dq"
}
}
],
"exec_env": {
"spark.databricks.delta.schema.autoMerge.enabled": True,
"spark.databricks.delta.optimizeWrite.enabled": True,
"spark.databricks.delta.autoCompact.enabled": True,
},
}
load_data(acon=acon)
Note: Although it is possible to interact with the Lakehouse Engine functions directly from your python code, instead of relying on creating an ACON dict and use the engine api, we do not ensure the stability across new Lakehouse Engine releases when calling internal functions (not exposed in the facade) directly.
Note: ACON structure might change across releases, please test your Data Product first before updating to a new version of the Lakehouse Engine in your Production environment.
Who maintains the Lakehouse Engine?
The Lakehouse Engine is under active development and production usage by the Adidas Lakehouse Foundations Engineering team.
Community Support and Contributing
🤝 Do you want to contribute or need any support? Check out all the details in CONTRIBUTING.md.
License and Software Information
© adidas AG
adidas AG publishes this software and accompanied documentation (if any) subject to the terms of the license with the aim of helping the community with our tools and libraries which we think can be also useful for other people. You will find a copy of the license in the root folder of this package. All rights not explicitly granted to you under the license remain the sole and exclusive property of adidas AG.
NOTICE: The software has been designed solely for the purposes described in this ReadMe file. The software is NOT designed, tested or verified for productive use whatsoever, nor or for any use related to high risk environments, such as health care, highly or fully autonomous driving, power plants, or other critical infrastructures or services.
If you want to contact adidas regarding the software, you can mail us at software.engineering@adidas.com.
For further information open the adidas terms and conditions page.